大数据测试,工作内容主要有:数据测试、模型测试;同时在不同的业务阶段,工作的重心不同,数据质量体系也会有不同的倾向,要全局的了解大数据测试,必须先明白大数据的架构,工作过程
大纲
大数据架构
常见的大数据架构主要有Hadoop(分布式文件存储、计算系统);由分布式文件系统(HDFS)/集群资源管理器(YARN)分布式计算框架(MR/mapreduce)构成;其中HDFS负责管理存储数据,YARN负责管理集群中的计算资源,调度和执行工作任务;
组件:核心组件如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
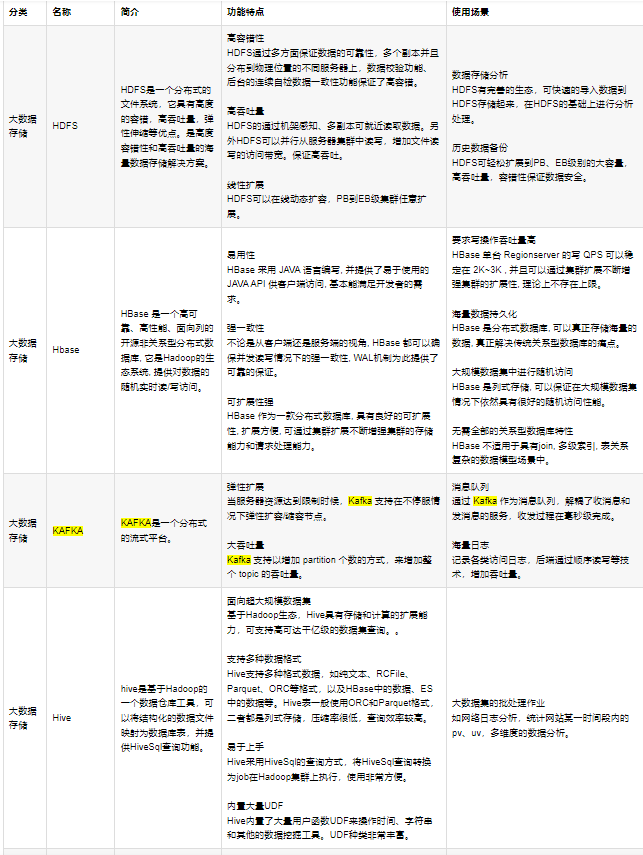
| HDFS:分布式文件存储系统;实际存储的是文件,有备份机制,支持数据一次性写入(每次写入生成一个独立文件),不支持数据修改,支持大规模的数据查询,特点是容错,高吞吐量,易弹性扩容;
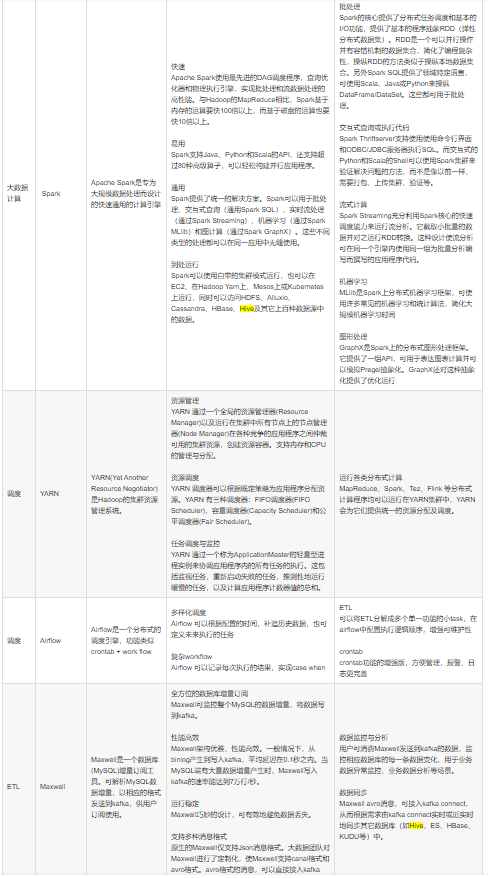
YARN:集群资源管理器,管理计算资源,进行调度和监控,其他计算引擎均通过yarn获取计算资源;
MR:计算框架,一般负责离线计算,大量数据计算,一般要通过hive来获取数据;
生态组件:
PIG:数据流处理(用于并行计算的高级数据流语言和执行框架);
HBASE:NSQL型的分布式数据库,本质是一个键值系统,底层数据存储在文件系统HDFS上;具有高可靠性、高性能、扩展性强的特定;
SPARK:分布式(内存)计算引擎,类似MR,但在内存中计算(因为在内存中不用读hdfs,所以性能有大大提升),提供各种库,可以使开发者用来实现数据流/批处理、交互式查询、ETL、机器学习、图像计算等场景;特定是快、易用、通用、兼容;
FLUME:日志采集系统,可用来对日志进行预处理;基于流式数据的架构,简单而灵活。具有健壮性、容错机制、故障转移、恢复机制;
FLINK:针对流数据(实时数据)和批数据(离线数据)的实时处理引擎,有着高吞吐、低延迟、高性能的特点;
SQOOP:数据导入导出,用来实现结构型数据(如mysql中的数据)和Hadoop之间进行数据迁移的工具。利用MR并行特点可大幅提升迁移速度,同时MR提供容错;
KAFKA:分布式消息队列,用来存储/传递消息(日志的生产/消费);特定是支持弹性扩展、大吞吐量的场景;
AWS S3 :存储服务组件,可用来存储各类数据和文件(HDFS);
SOLR:用于搜索索引的全文检索服务器;
数据查询引擎:
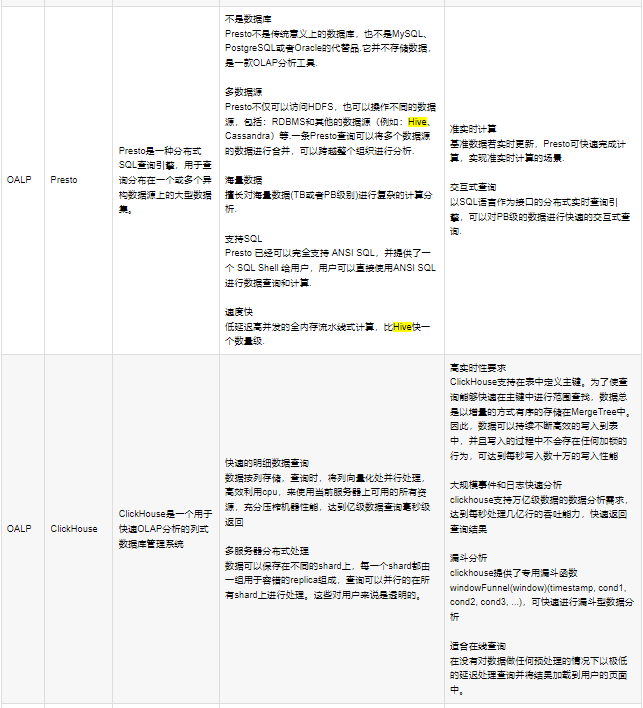
HIVE S3:数仓工具,提供数据汇总和命令行即席查询功能;能将hdfs文件映射成一张表,能有sql来查询这个表的数据,同时能就sql命令转换成mr任务执行;支持多种格式文件,用于超大规模数据集场景;
IMPALA:高效的基于MPP架构的快速查询引擎,基于Hive并使用内存进行计算,兼顾ETL功能,具有实时、批处理、多并发等优点;
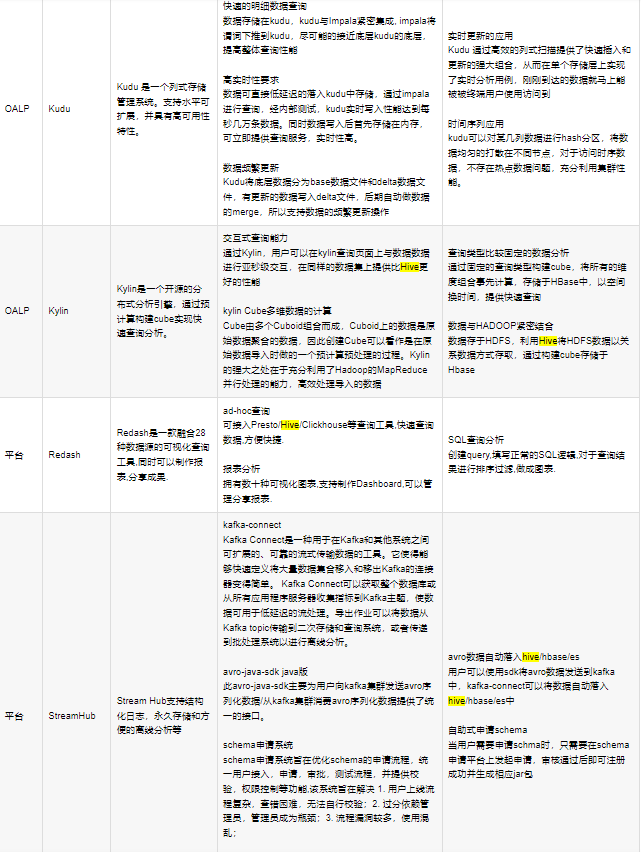
KYLIN:开源分布式分析型数据仓库,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力,支持超大规模数据的压秒级查询(和视图有点点类似);查询比hive快,通过预计算构建cube实现快速查询;
PRESTO:开源的分布式查询引擎,支持多数据源,大量级数据的场景;
ETL:数据处理的过程,指数据提取(extract)、转换(transform)、加载(load)的过程;
组件众多。不同组件提供不同能力,Hadoop框架,很像Android系统,是一个底层的数据框架。
|
组件特性:

参考架构:

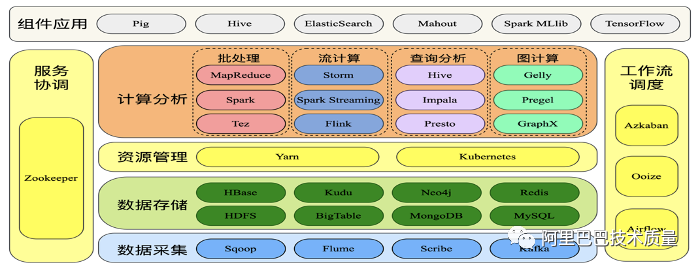
传易音乐大数据架构
传易hadoop
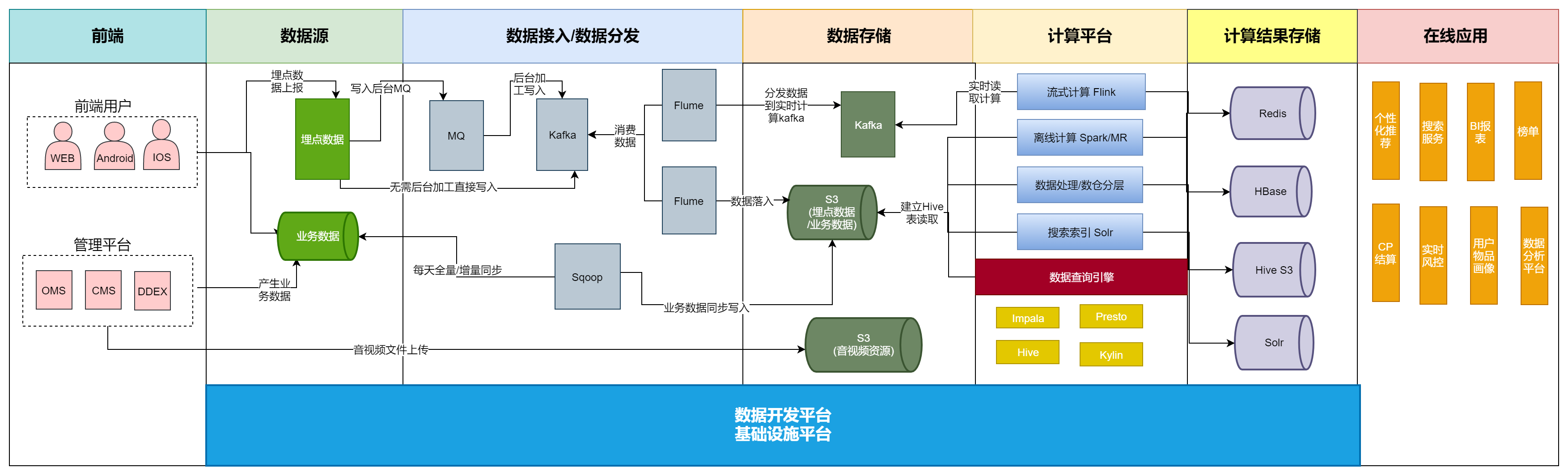
传易数仓架构
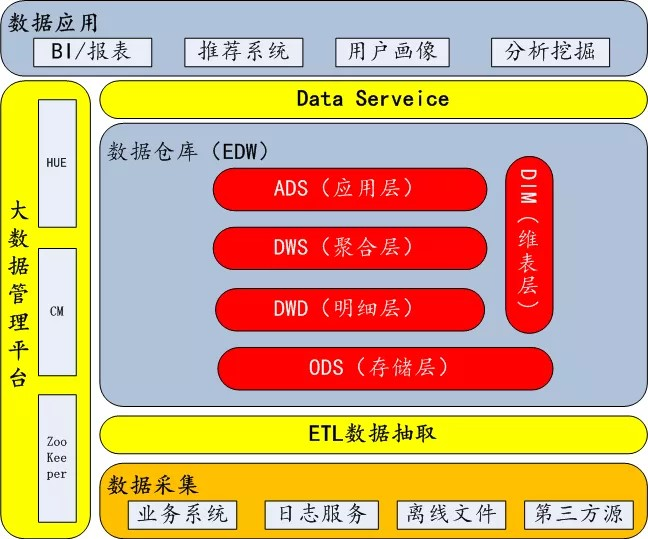
数据架构(数仓)
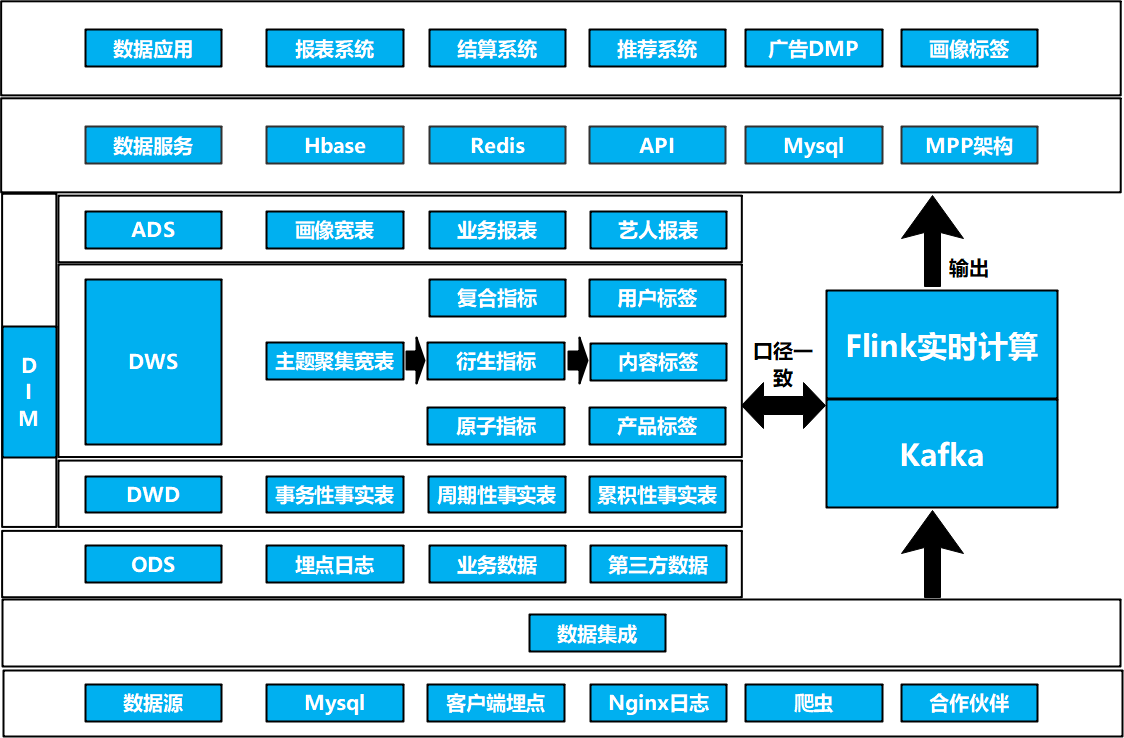
数据架构–横向数据分层

数据架构–纵向数据分层
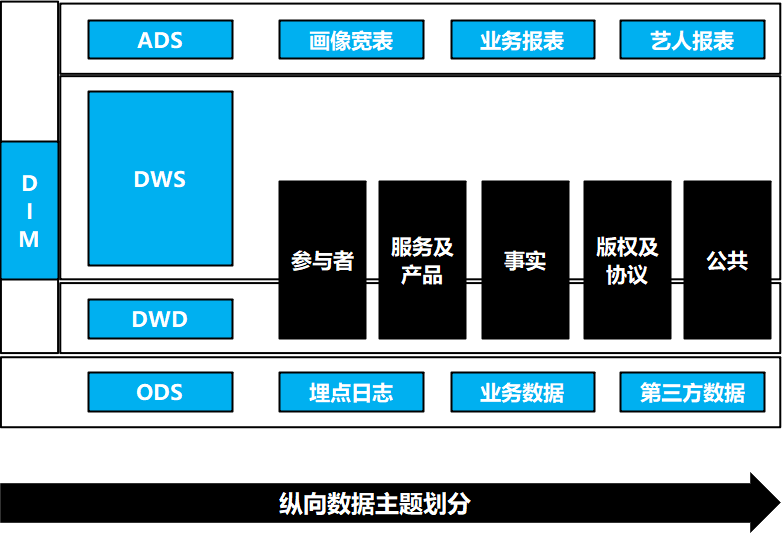
传易大数据架构总述:
传易架构的特点是处理的数据量大,数据来源复杂,人员多,业务应用广;存在无文档资料维护;测试介入低,质量不可度量;无测试环境,依赖线上数据开发测试,流程不规范,安全性差;缺乏标准和度量体系,投入产出比无法度量等问题;
数据测试
数据测试前,需要对数据质量形成共识;数据的价值是由需求方决定的,能满足需求方/使用方需求的数据才能称得上好数据
标准
数据质量评测方向
数据质量我们一般从以下六个维度评判,同时我们往往还需求考虑数据的(+安全性),评价这些维度往往需要用到监控数据和历史数据:
1
2
3
4
5
6
| 完整性:数据不多不少。数据条数完整,类型完整,参数完整;不重复,看是否有异常类型或者异常值(枚举外);
准确性:结果准确,抽样准;表内横向准确,表间/数据链路间的数据准备或一致,参数数据分布准确;
及时性:实时数据性能满足需求,各组件性能满足要求;如用户余额,抽奖次数等,主要受任务调度、优先级、处理耗时影响,一般关注整体和局部的耗时情况;
一致性:前后数据一致,参数和总体满足逻辑一致,如订阅总额=订阅单价*时长
有效性:数据是有效的符合数据规范,如email数据、身份证数据规范
唯一性:数据唯一,如每个用户的boom_id,每个音乐的music_id
|
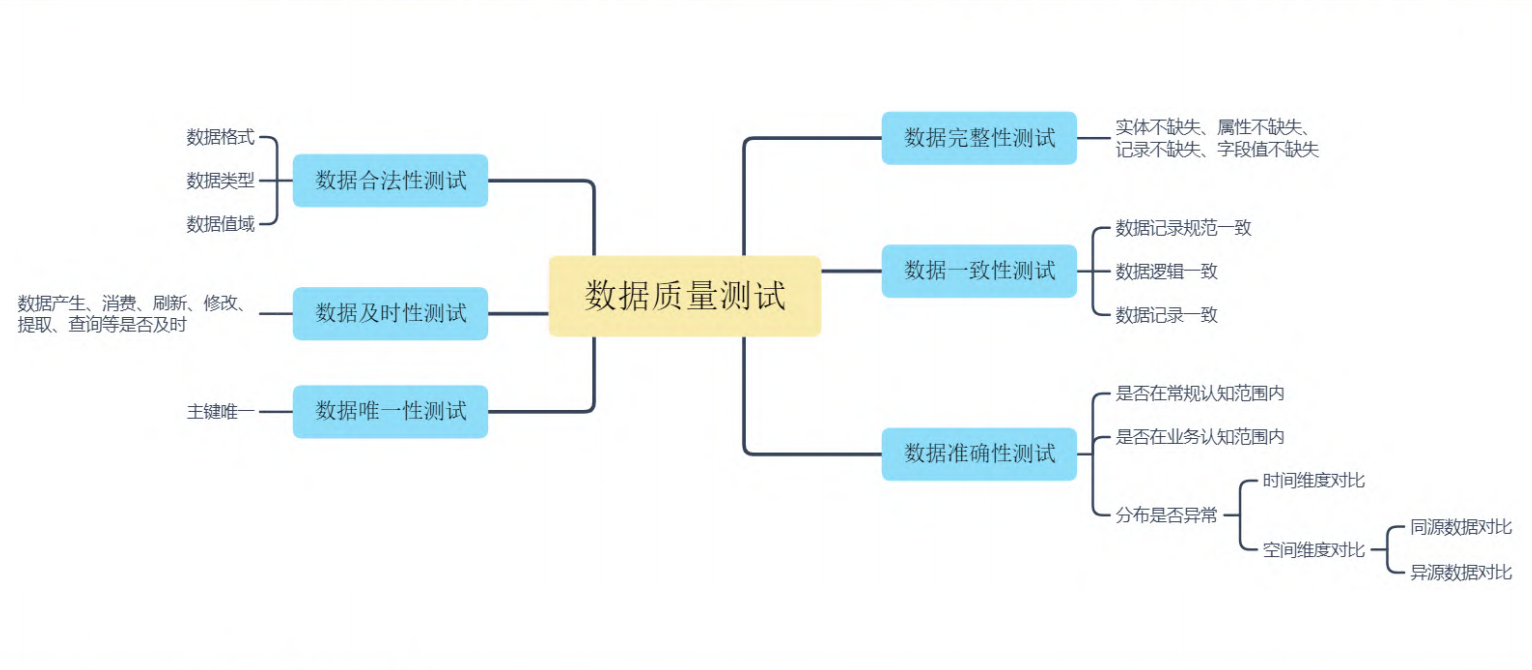
以上是测试时评判的方向,测试过程也需要有标准来评判有效性,如下:(理论不同对象/不同阶段都应该有标准)
测试活动度量标准
数据质量度量标准
除了测试时,需要考虑的场景外,还需要对整体的数据质量好坏进行评判,以下为数据质量的优劣评判标准
1
2
3
| 98%:全年可用天数达到98%以上,即服务不达标天数全年不超过7天。
基线时间:核心 SLA 基线产出时间需满足业务要求。
是否易于使用:及其他非质量熟悉标准(见MFQ)
|
以上指标为传易的定量的标准,以下为美团的定量的标准
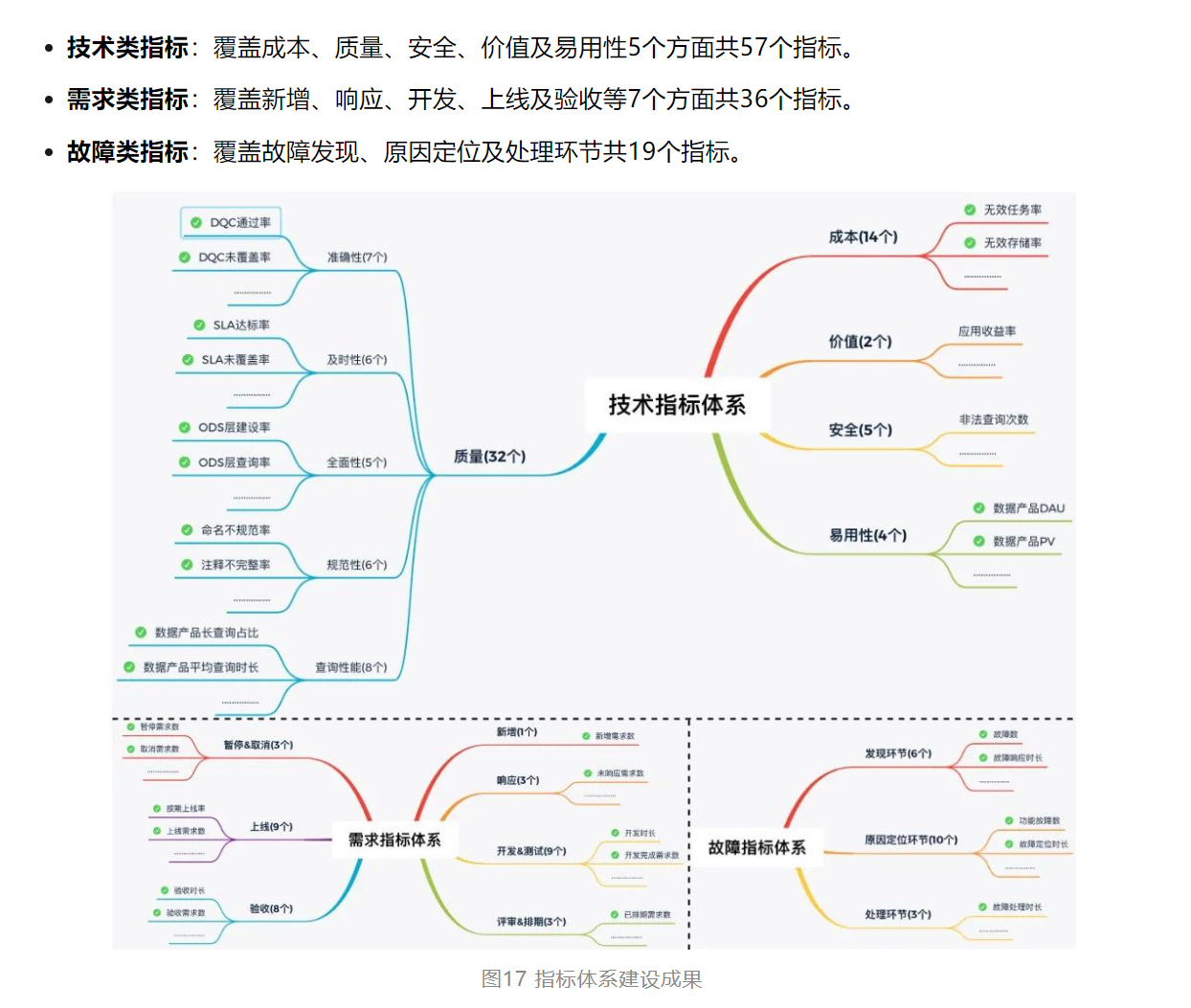
数据质量评测流程
要想把控数据质量,往往需要介入数据的全生命周期;需要有标准可依,有规范进行约束,有监控数据可查,有工具可用来进行评测,流程结果可量化,并且可以持续运营迭代体系:
1
2
3
4
5
6
7
8
9
10
| 业务分析--分析数据流(流程图)、数据特性(计算型/时效型)
设计阶段--数据类型、数据处理逻辑、数据链路、数据服务
数据标准--量化的数据标准,作为内外部的规范和约束
数据监控--数据监控能力,是否有全链路监控能力
数据卡点--针对不同阶段的数据(流程)是否有卡点,能进行评测和定位问题
数据环境--如何低成本,高效的维护数据测试环境
构造数据--如何快速有效的实现可复用数据构造能力
数据评测--如何保障评测的有效性、覆盖率、标准化
数据量化--如何实现数据流程、质量、评测的量化,让过程结果更公开透明
迭代优化--如何管理问题,运营数据,归纳形成标准,持续的优化体系
|
测试执行
数据治理可参考的切入阶段

数据质量三板斧
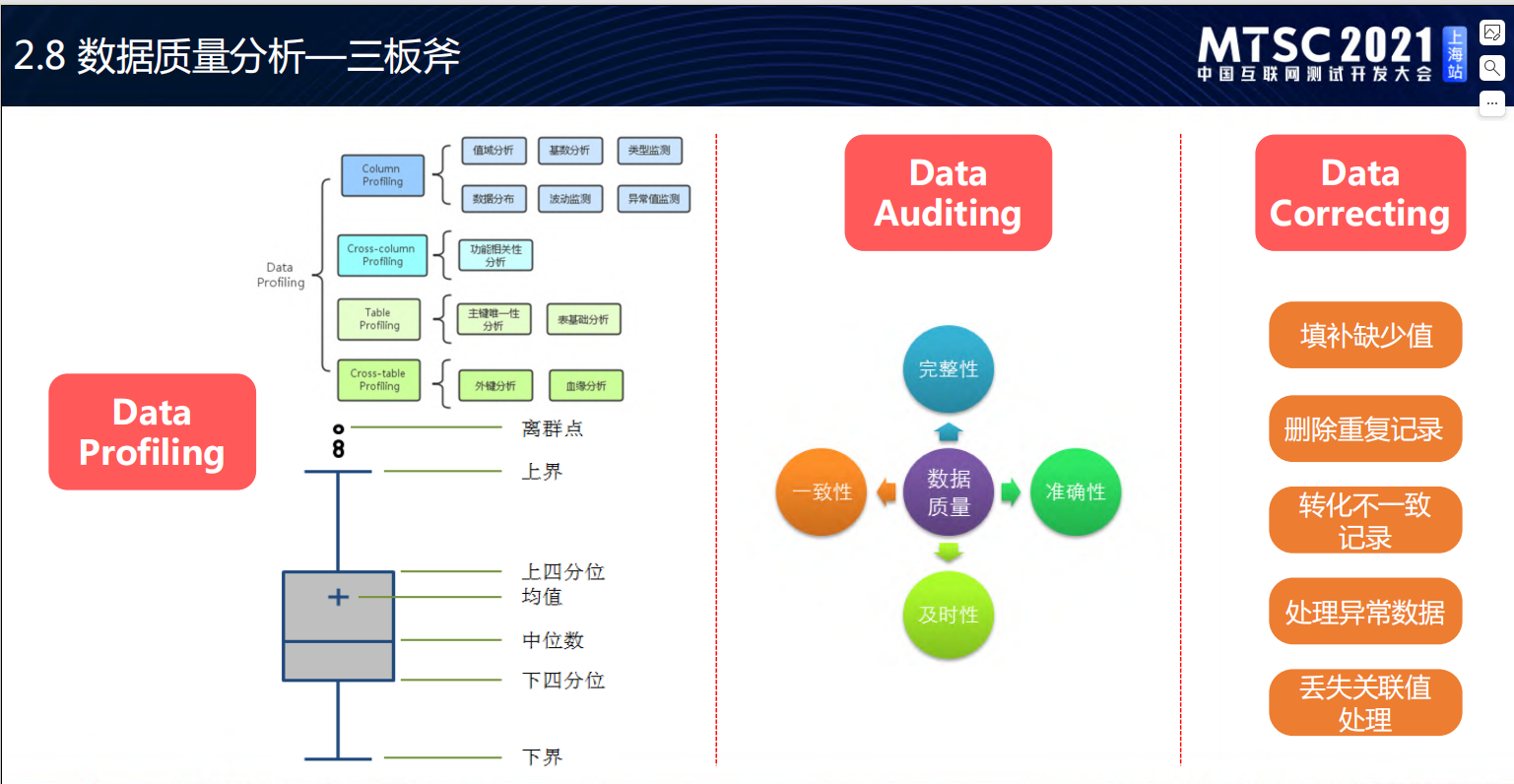
数据功能测试
三板斧:数据分析技巧

测试范围

功能测试,很重要的一环是ETL:ETL测试维度
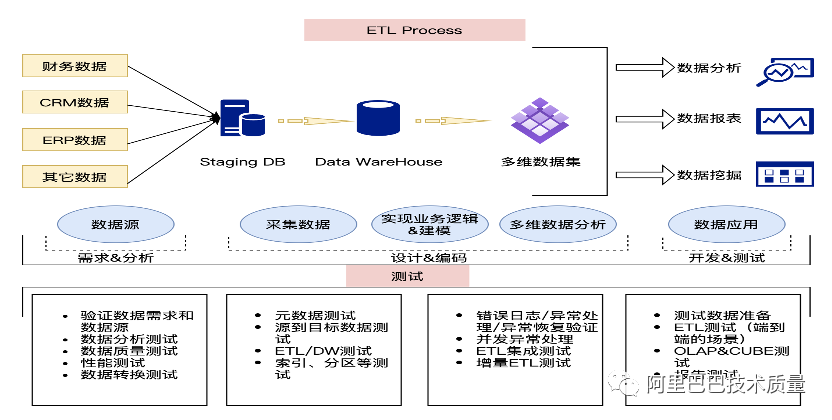
离线ETL测试步骤:核心在数据
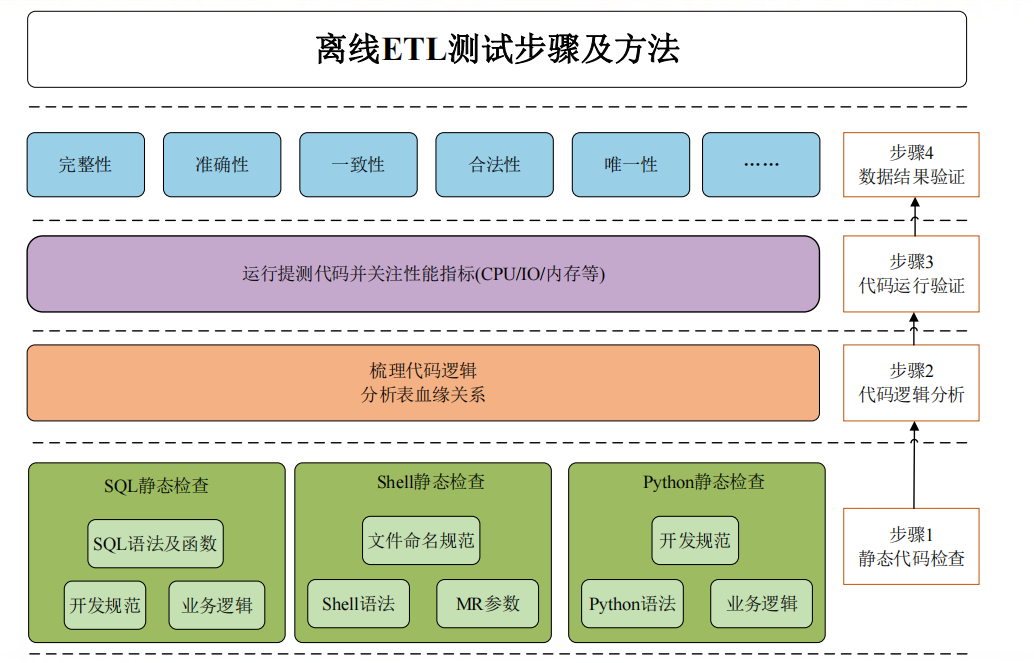
实时数据ETL:核心除了数据、还有性能
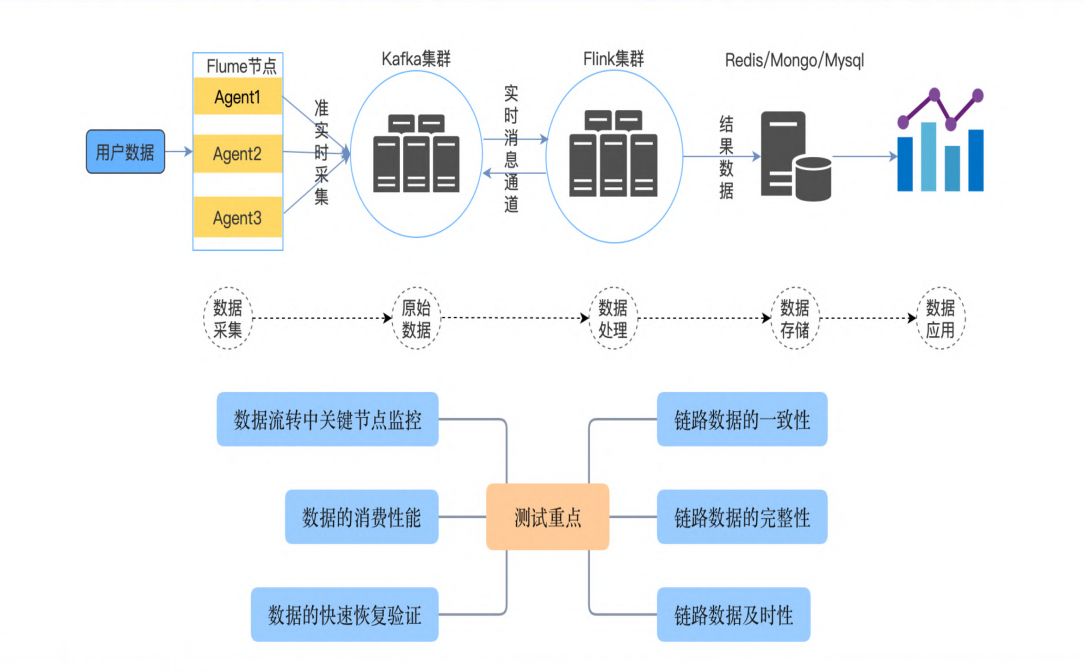
数据仓库分层测试

项目测试经验
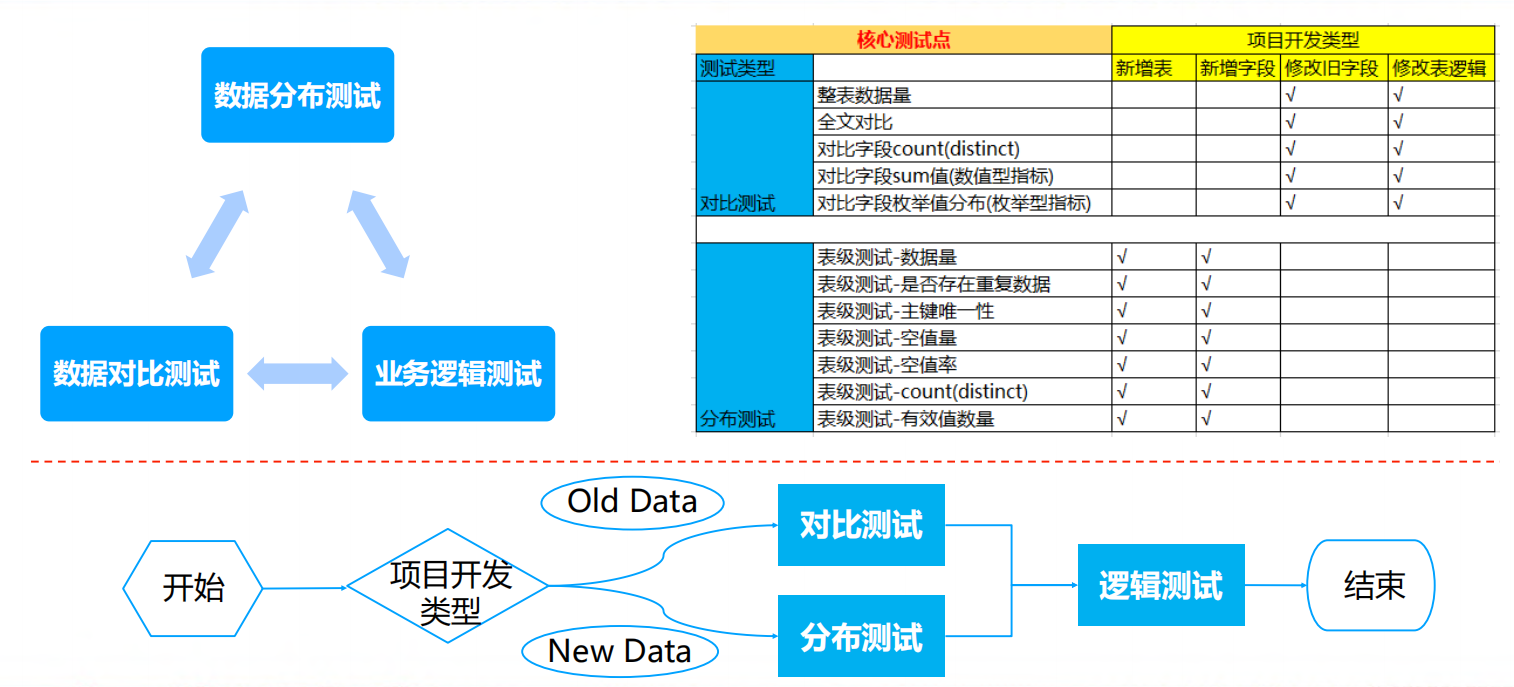
数据性能测试
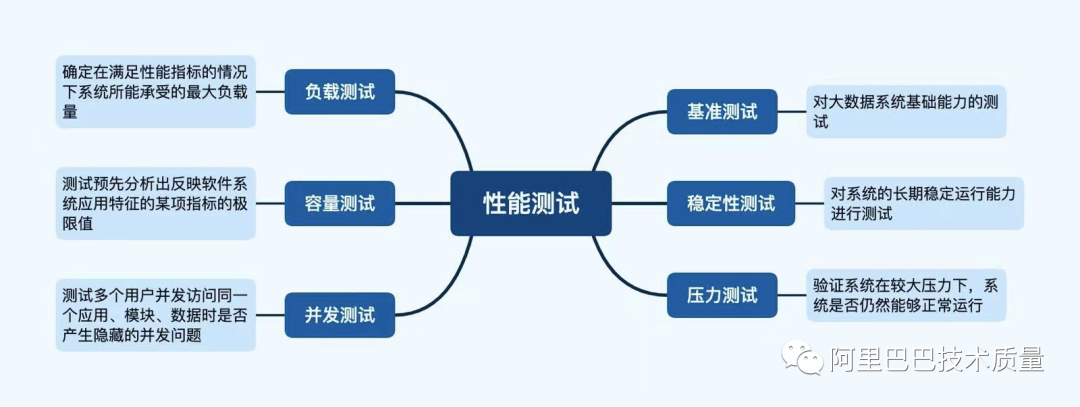
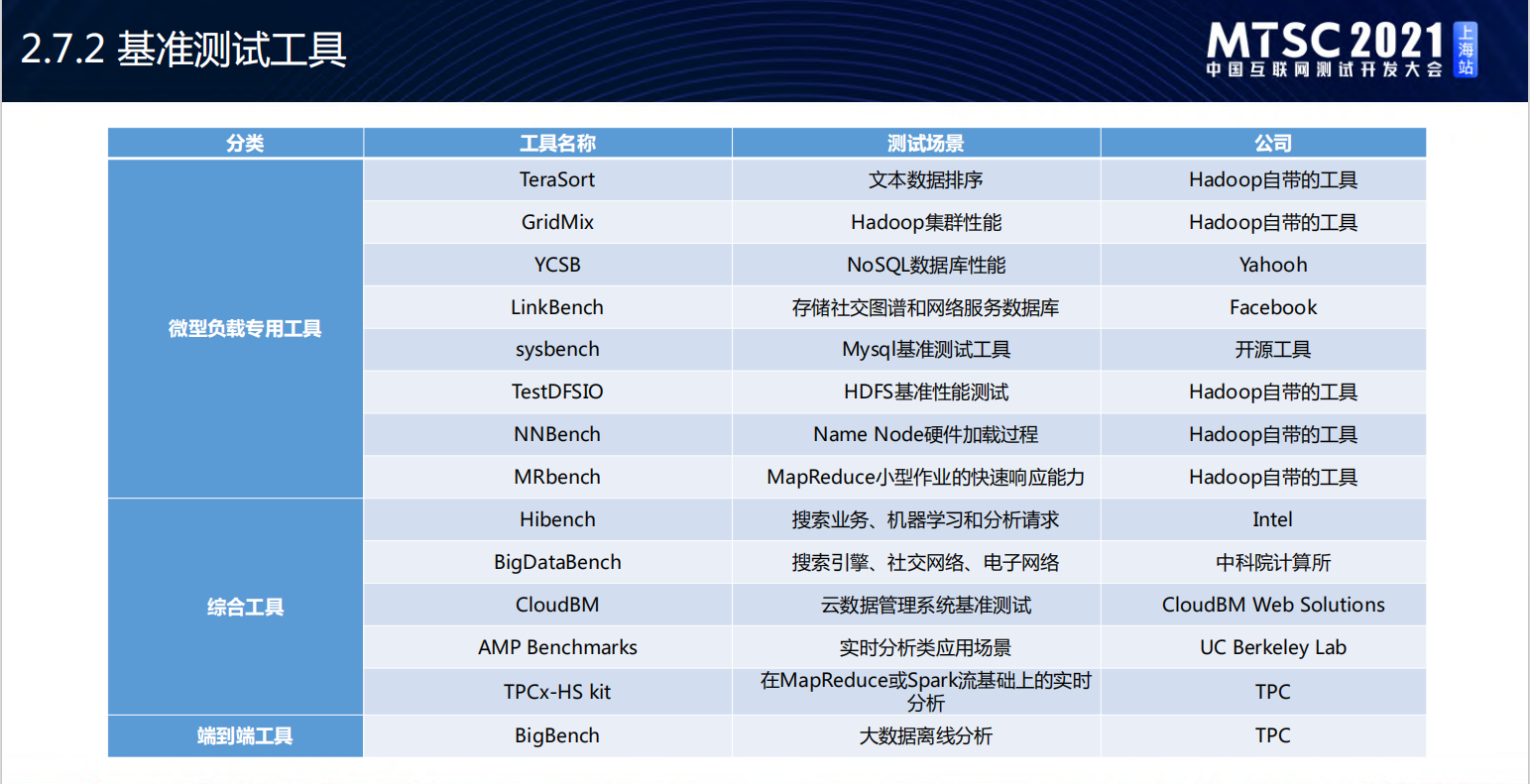
大数据性能工具:
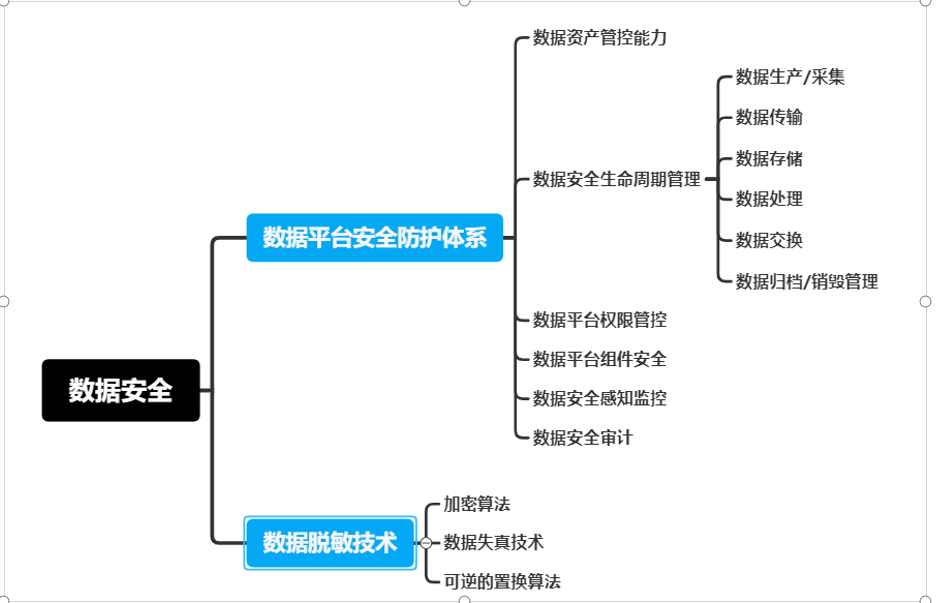
数据安全测试
以上的数据质量评测标准未说明安全情况,数据安全需要考虑数据本身的安全(隐私脱敏),流程安全,权限管控、安全监控,故在此处说明,安全需要覆盖的场景如下:
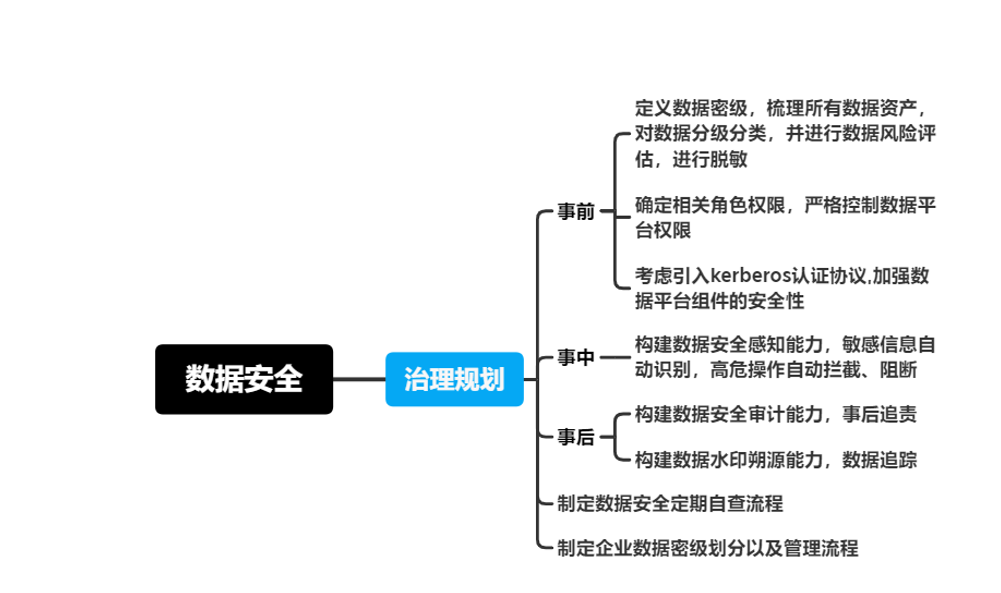
数据安全实施策略
数据质量问题处理链路
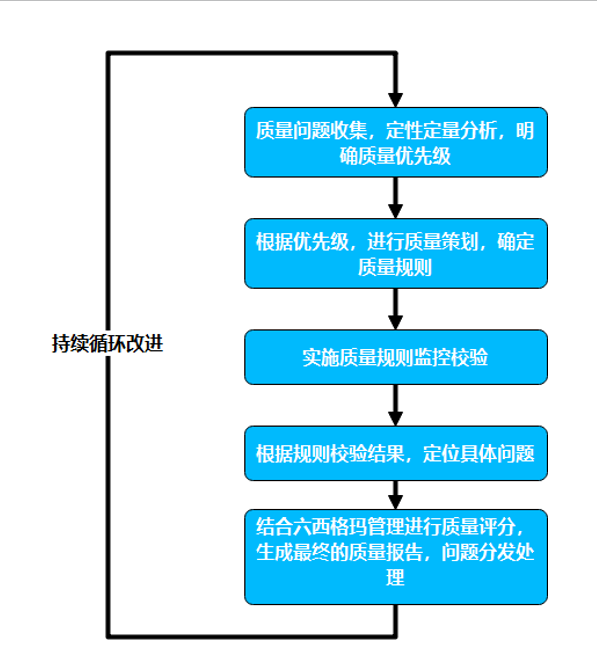
数据治理工具
开源框架
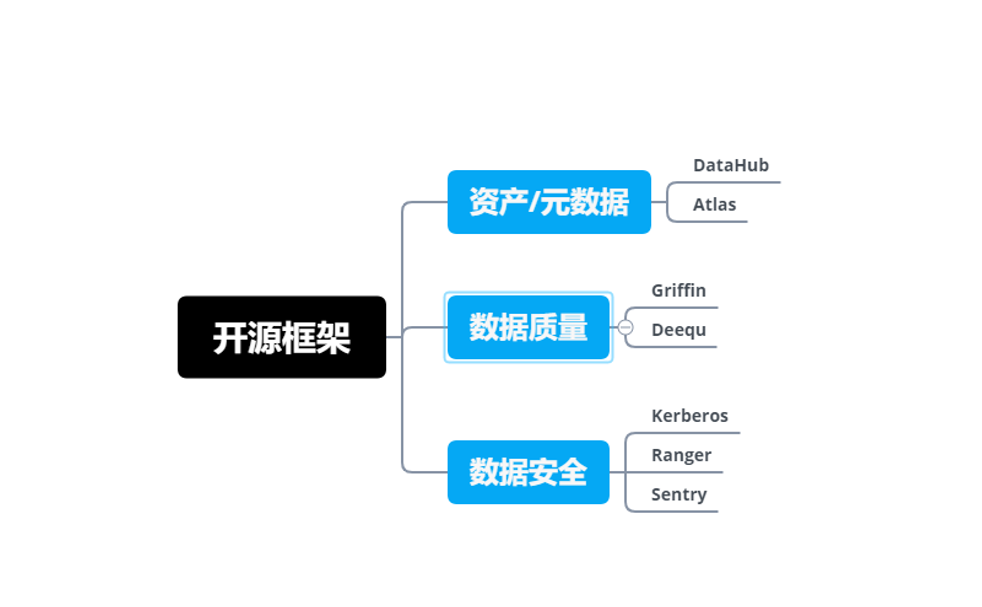
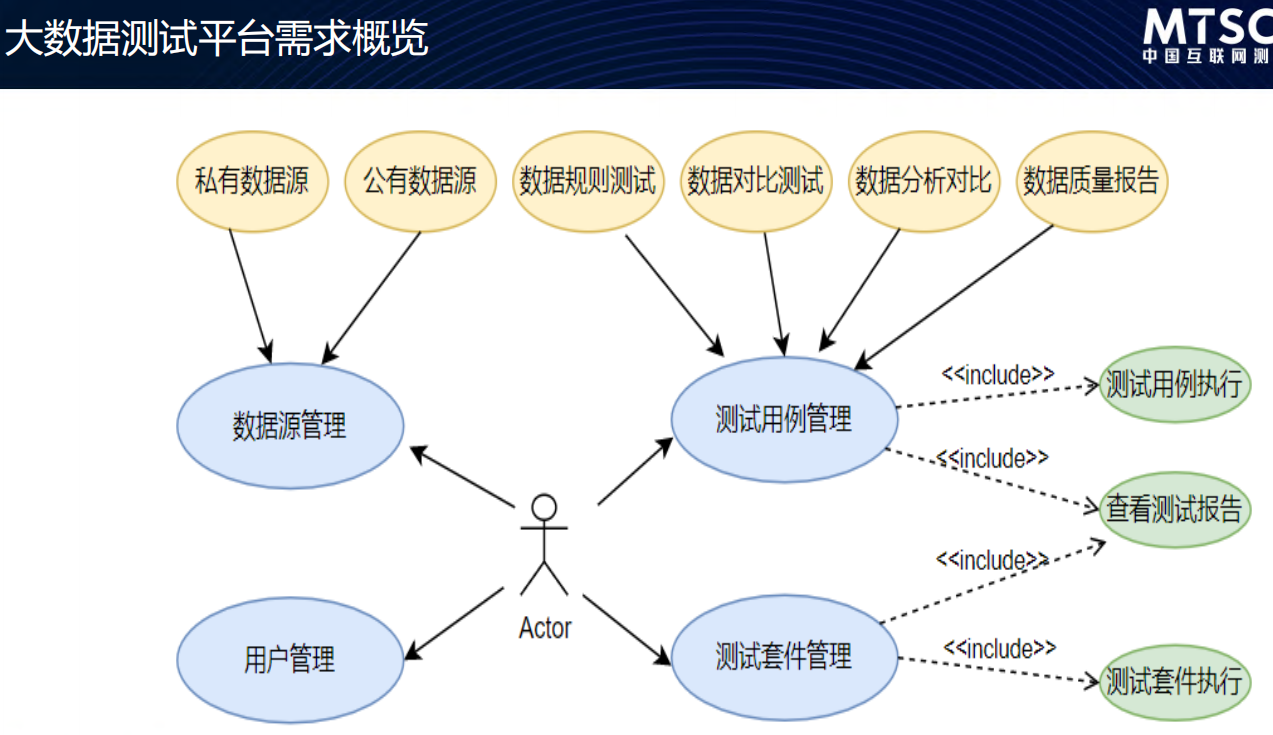
大数据测试工具

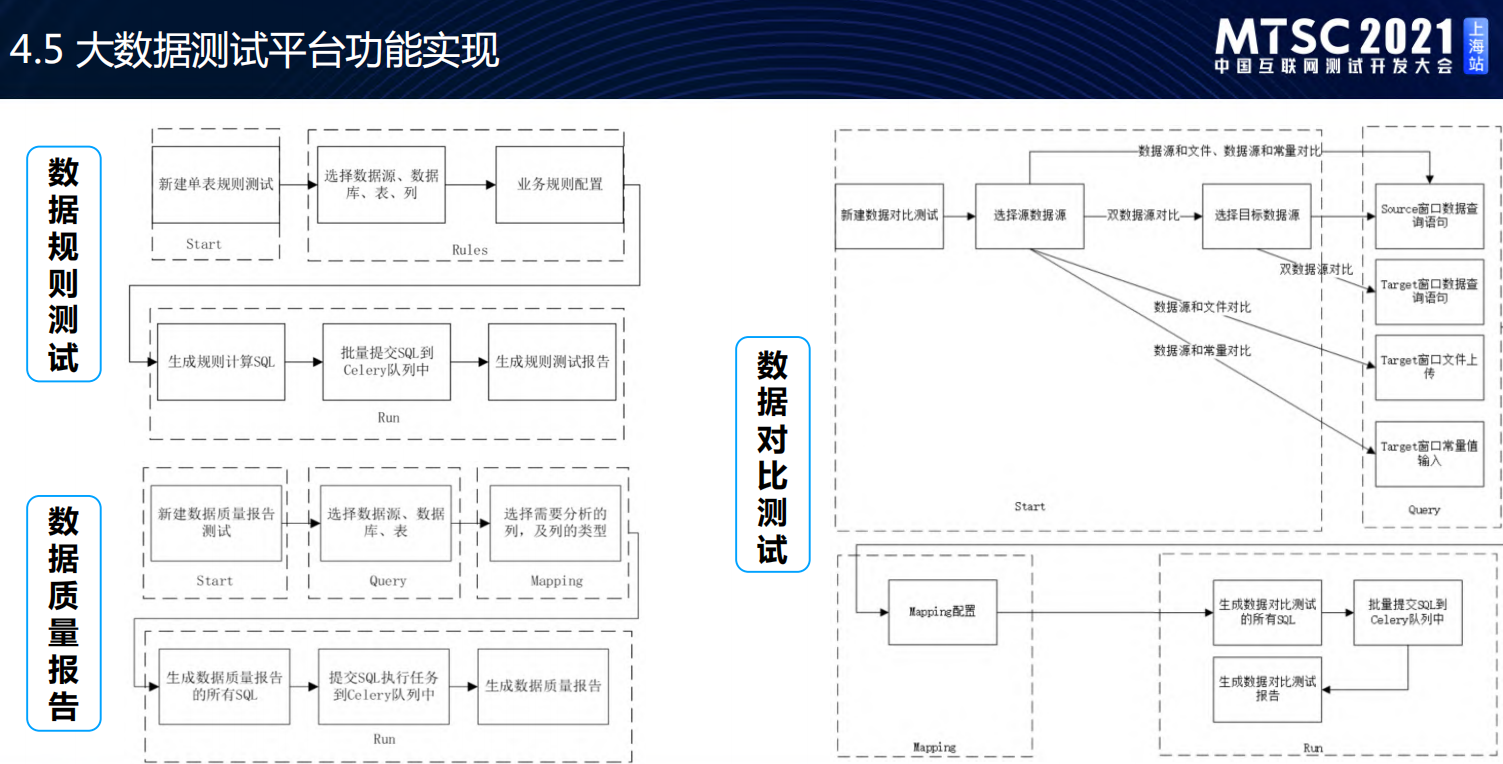
大数据测试平台架构
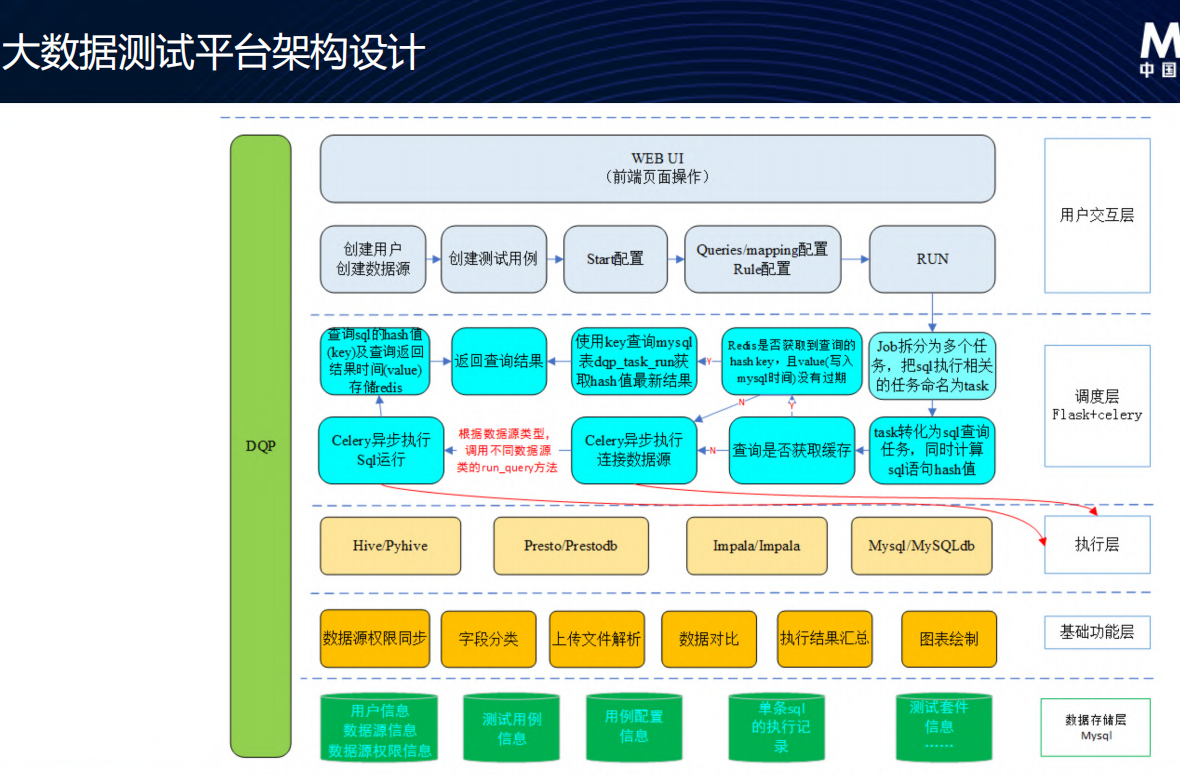
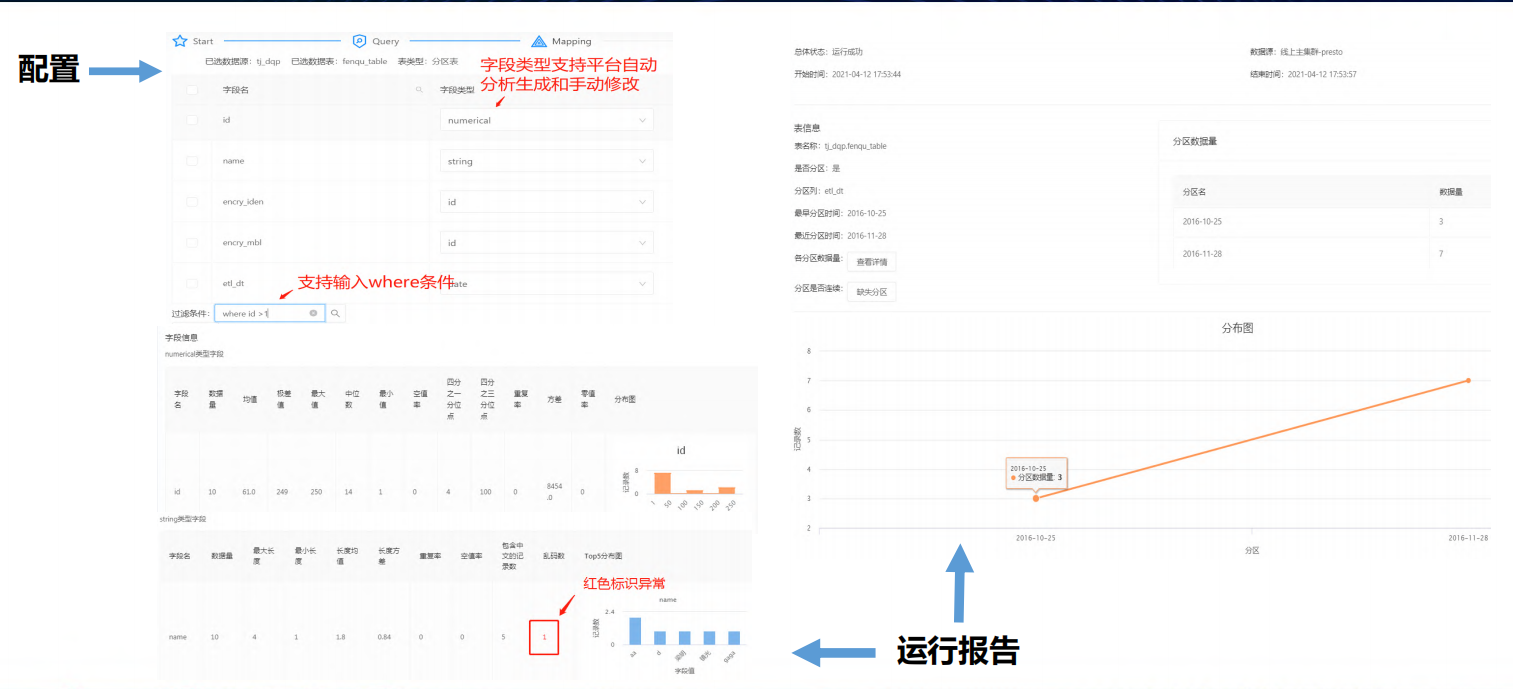
- 大数据测试平台-参考质量报告
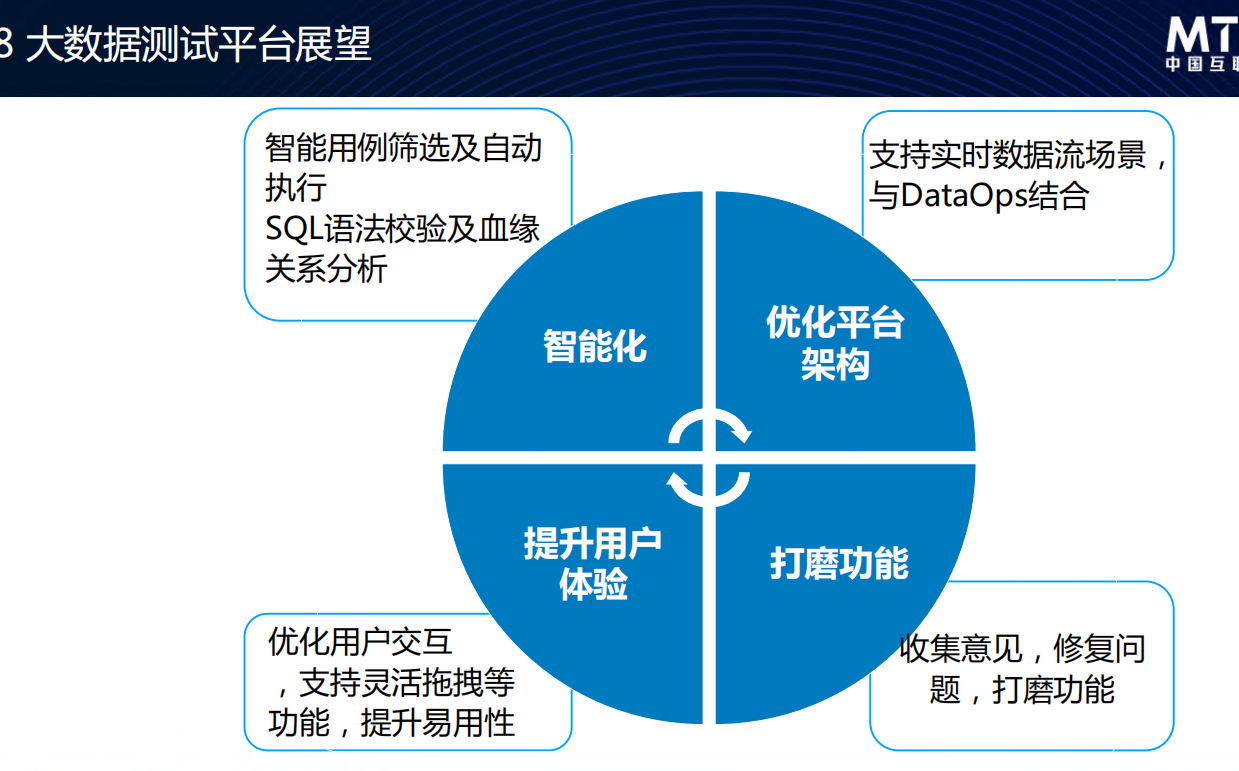
- 展望:看起来是朝线上监控化的方向走
模型测试
广告-模型测试
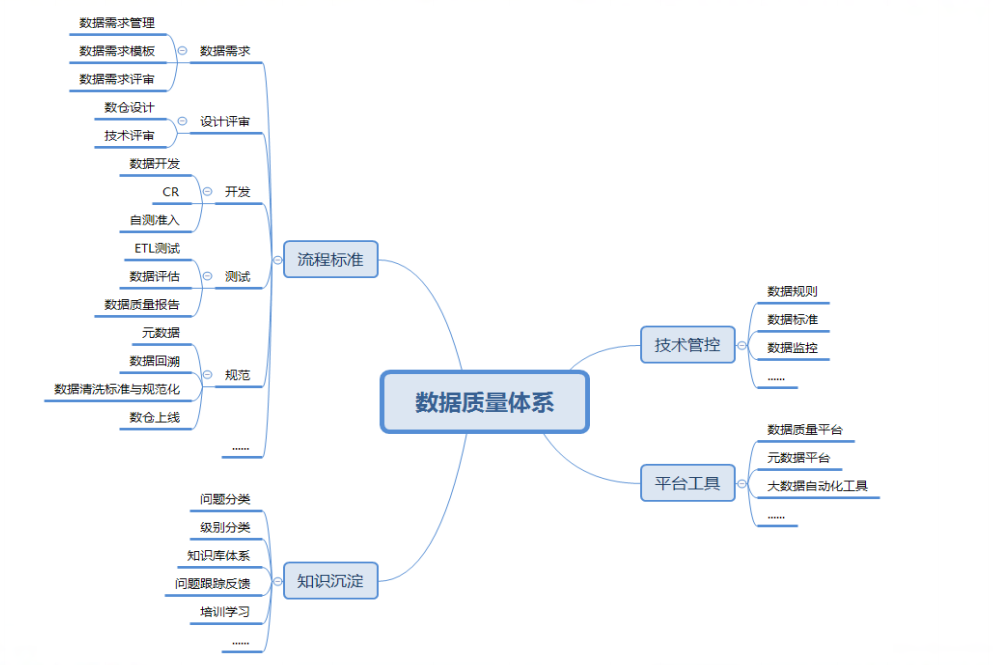
大数据质量体系
数据质量活动需要遵循:有标准、有数据(监控)、可量化(度量)、自动化的原则;质量体系总结如下:

v1.5.2